Structural Hierachy
The structure of a protein is generally understood in terms of an organizational hierarchy that consists of protein sequence, local secondary structure, tertiary structure, and finally quaternary structure. The study of protein structure in these terms has led to a greater understanding of the underlying physical principles that control the conformation and function of proteins. This hierarchy also reflects one conceptual view of protein folding, where the local secondary structural elements form first, followed by the tertiary and quaternary structure. The following discussion of protein structure is organized according to the preceding hierarchy.A. Primary Structure
The character of a protein is determined by the amino acid sequence and composition of the polypeptide chain. By convention the order of amino acids in a protein is listed starting at the N-terminal and ending at the C-terminal amino acid residue. The N-terminal amino acid carries a free amino group, whereas the C-terminal residue retains a free carboxyl group. These terminal residues of the polypeptide chain are also referred to as the amino and carboxy terminus of the protein, respectively. Almost all protein sequences are determined indirectly by DNA sequencing. Chemical sequencing, either by automated Edman degradation or by mass spectroscopy, is still necessary to identify a protein from its original source and to prove the presence of post-translational modifications. All sequences of interest should be examined for errors by resequencing and comparison with orthologous proteins.
B. Conformational Restrictions on the Polypeptide Chain
The amino acids in a protein are linked by an amide linkage that is referred to as the peptide bond (Fig. 3). There are several key features to this bond. It is planar as a consequence of the partial double bond character of the carbon–nitrogen bond. It is almost always in the trans configuration. The peptide bond is fairly rigid where the barrier to rotation is ∼20 kcal/mol. The carbonyl oxygen and amide hydrogen carry a partial negative and positive charge, respectively, which allow each of them to form a hydrogen bond. This linkage profoundly influences the stability, conformation, structure, and function of proteins.
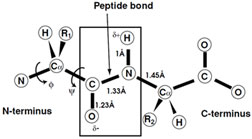 |
| FIGURE 3 Schematic representation of the peptide bond and the observed restraints on the conformational. |
Conformational energy calculations and experimental observations based on high-resolution X-ray structure determination show that generally only ∼8% of the possible combinations of ø and ψ are strictly allowed, whereas more generous energy considerations include a total of 20% (Fig. 4). These allowed regions of conformational space fall into three areas that are occupied by the major secondary structural motifs observed in protein structures. As indicated these belong to right- and left-handed α-helices and β-sheet.
Support our developers




