Publishing and Finding Images in the BioImage Database, an Image Database for Biologists
I. INTRODUCTION: THE NEED FOR IMAGE DATABASESImages and videos form a vital part of the scientific record. While the significance of the various genome publications is beyond dispute, attention has now shifted to the organization and integration of information within cells, where the need for functional analysis of gene products is universally recognised. The significance of microscopy images in the process of determining the spatiotemporal expression patterns of gene products cannot be overestimated. The volume of such images is also significant. In a single day, an active cell biology lab may generate between 5 and 50 Gbytes of multidimensional confocal image data or digital video data.
We recently wrote to a colleague requesting a copy of a beautiful confocal image that he had collected some years ago while a graduate student in Heidelberg, which showed the expression sites of a particular gene in the developing mouse embryo. His reply typifies the wasteful fate of an unfortunately large proportion of biological research images, and is perhaps the best possible argument for a publicly funded image database that can provide free access to and a safe repository for such images:
-
Concerning the image data you requestedmthis is a
tough one. The image was recorded about ten years
ago, and I never managed to write a paper about the
work so it was never published. The original data (if
they still exist) must be on some magneto-optical disk
in one of many boxes in my flatmquite hopeless to find
at short notice. All I can promise is that I'll look into
this once I am back from my travels, but that will take
a few months. Whether anyone still has hardware
capable of reading the disc is quite another matter!
Sorry about this.
The European Commission-funded ORIEL Project (Online Research Information Environment for the Life Sciences; www.oriel.org), coordinated from the European Molecular Biology Organization in Heidelberg, is developing tools and procedures to promote access to and integrated retrieval of various types of digital biological information. Within this umbrella project, the BioImage Database project (www.bioimage.org) has four purposes: to provide the scientific community with a freely accessible database and archive of highquality multidimensional digital images of biological research relevance, with deep descriptive metadata; to make the images and their metadata available electronically via the Internet for personal study, educational, commercial, medical, and scientific research purposes; to provide tools to assist in the submission, downloading and visualization of such images, and in making comparisons between them; and to provide links between these image data and other relevant digital items of biological information (Shotton, 2003; Shotton et al., 2003).
Taking its name and concept from an earlier BioImage Database prototype (Carazo et al., 1999; Carazo and Stelzer, 1999; Lindek et al., 1999), the BioImage Database has been completely redesigned and rewritten within the Image Bioinformatics Laboratory of the Department of Zoology at Oxford University and it is now standards-based, using open source components throughout and employing semantic web technologies to provide a semantic reasoning layer between the users and the stored metadata. Central to these is a newly written ImageStore Ontology that defines the metadata descriptors used for the images and through which all user interactions with the database occur (Catton and Shotton, 2002; Sparks and Shotton, 2003). We are now starting to populate this publicly accessible BioImage Database with images from biological journals, individual researchers, learned societies, and research collections, with the intention that it should become for biological images what the standard bioinformatics databases are for sequences and structural data, with an emerging culture of image submission to the BioImage Database of high-quality research imagery arising from publicly funded biological research.
Our motivation in creating the BioImage Database is the belief that images are important assets created by the scientific process, but that they are only useful if they can be found by those interested in viewing or using them. Images held on unlabelled slides in desk drawers, dusty stacks of CDs, or forgotten discs in cardboard boxes are not scientific assets but liabilities. The purpose of this article is to bring the BioImage Database to your attention and to invite you both to submit your image collections for publication in the BioImage Database and to use its contents for your own research and teaching activities.
II. METADATA IN BIOIMAGE
Accurate and detailed metadata (data about data) are essential for finding images in a databse because, unlike sequences and text, images are not selfdescribing. While it is possible to scan through a sequence and recognise particular codons or transcription factor binding sites or to search a text document and extract key words that can be used to rank the relevance of a document to a query, the development of software that can identify the contents of an image by analysing its pixels is in its infancy. Thus without appropriate metadata, images are difficult or impossible to find, and online databases become little more than meaningless and costly data graveyards. Unfortunately, the process of manual metadata submission can be time-consuming, which is a disincentive to sharing information. Traditionally, there has been a tension between the cost of investing this effort "up front" at the time of image creation and storage and the subsequent benefits gained in terms of ease of image location and retrieval. The BioImage Database attempts to assist in the metadata submission process both by simplifying the submission of metadata by authors and by automating the harvesting of prerecorded metadata from image files, as described later.
The image metadata within the BioImage Database relate to several domains.
A. People and Institutions
With the consent of the authors, the BioImage Database holds contact information (names, postal and e-mail addresses, phone and fax numbers, etc.) about the people responsible for conducting experiments and creating the submitted images, the institutions in which they work, and the agencies that have funded their research. The data structure is flexible enough to record individuals' affiliations to several institutions, either simultaneously or sequentially, as appropriate.
B. Studies, Databases
Publications, and External Within the BioImage Database, the fundamental unit of record is the BioImage Study, roughly equivalent in scope to a peer-reviewed scientific paper. Indeed, a BioImage Study will normally be hyperlinked to one or more scientific papers based upon the image data contained within the study. From these studies, users may also make direct links to the principal taxonomic, structural, and sequence databases, permitting the BioImage Database to be used for lateral access to the wider scientific literature and other relevant factual data.
C. Experiments, Data Sets, and Images
The findings included within a Biolmage Study may have been obtained from several experiments. All the images resulting from a single experiment, typically obtained from observation of similar specimens (or a single one), constitute a single BioImage image set. However, image sets do not necessarily have to be associated with particular scientific experiments. Collections of images on a related theme, e.g., historical time-lapse cine footage of mitosis in Haemanthus, may be grouped together into a single image set, even though they were not all obtained during a particular experiment.
D. Media Objects
An experiment may result in the creation of one or more media objects, e.g., images, videos, and models, which may be of any type or dimensionality-conventional 2D images, 3D, or 4D (x, y, z, and time) images comprising one or more fluorescence channels, videos, animations, surface reconstructions, etc. Ancillary data in the form of interpretive diagrams, graphs, tables, etc. may also be included. The BioImage data model is capable of recording all the basic details concerning these media objects. For example, for a conventional 3D confocal image, metadata would include the file format and size, the compression codec and quality settings, the x, y, and z pixel resolutions and pixel dimensions at the image plane, the corresponding optical resolutions at the image plane, the x, y and z data acquisition speeds, and the wavelength characteristics of each separate imaging channel. The provenance of the image is also recorded, showing when and by whom it was created and entered into the BioImage Database, how it may have been derived from another image, and, if so, the image processing and/or compression algorithms that have been used. Thus, for example, one might record the algorithm and point spread function parameters used to produce a blurfree deconvolved 3D image from a set of raw fluorescence optical sections showing out-of-focus blur. Similarly, if a section of video is submitted for publication, the BioImage Database can record details about the source file from which it was edited and the original tape or disc upon which that original was recorded.
E. Semantic Metadata
The metadata domains described so far cover only who created an image and when, where, how, and why it was made. They do not tell us what the image actually represents, and its significance, and these are arguably the most important kind of metadata (Shotton et al., 2002). Many image databases fail to distinguish adequately between the content and the meaning of an image or to take into account different interpretations of the same data. Within the ImageStore ontology, we make a clear distinction between what the image represents (i.e., what is being denoted in the imagem the species, cell type and preparation conditions of the specimen, and the identifiable features within the image) and the connotations attached to the image (the interpreted meaning, purpose, or significance of the image, its relevance to its creator and others, and its semantic relationship to other images) (Catton and Shotton, 2002, 2003). In addition, we use external ontologies and taxonomies to assist in the description of image content, instead of relying solely on conventional key words. Currently we are using GO ontology (http://www.geneontology.org) to describe genes and gene products and NCBI taxonomy (http://www.ncbi.nlm.nih.gov/Taxonomy/) to identify species.
III. HOW TO SUBMIT IMAGES TO THE BIOIMAGE DATABASE
Via the BioImage home page (www.bioimage.org), users may apply for a submission account to the BioImage Database. They will then be supplied with a username and password that will permit them to use the submission service. On entering the service, the user may enter or update personal details and is presented with a list of previously submitted BioImage Studies that may be edited and the option to submit more.
While at the time of writing the details have yet to be fully worked out, the BioImage Database intends to adopt two complementary approaches to submission-manual and semiautomatic. The manual submission interface is interactively customized for the type of submission to be made (e.g., entry of the accelerating voltage will be requested for submissions of electron micrographs but not of light micrographs), with the submission forms being generated dynamically as appropriate from the structures within the ImageStore ontology and any approved auxiliary ontologies. Any new submission starts at the BioImage study page and progresses to subsequent pages according to related resources required. Each page allows the user to enter appropriate values for that resource's attributes.
For example, a user may start the submission of a new study by entering its title and a brief textual description in the study page. The user may then wish to describe an experiment within that study, bringing up the experiment page within which (s)he can enter details of the technique used and specify the parameters used for image capture and subsequent digital image processing. The user effectively creates a tree of resources, each with its own defining attributes, which may be navigated, modified, pruned, and expanded before being finally committed to the database. An example is shown in Fig. 1.
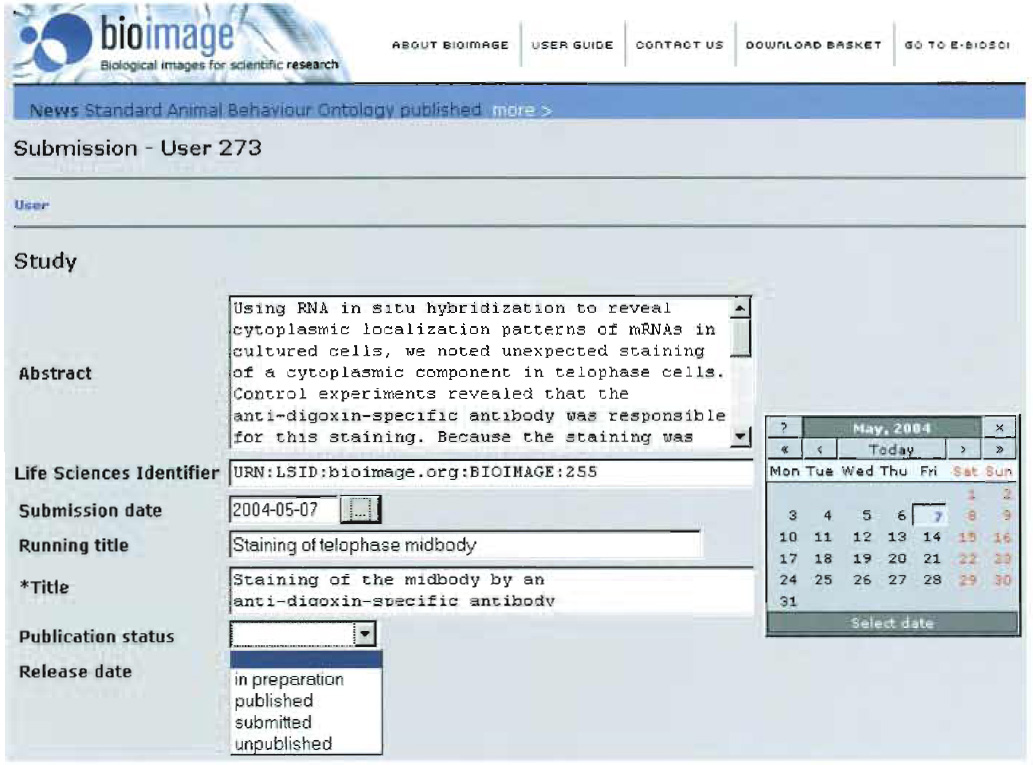 |
| FIGURE 1 A BioImage database submission interface. |
Many of the metadata required to document an image may already be available in digital form, e.g., in the headers of image files generated by modern research microscopes and digital cameras. By capturing this information at source, the process of managing images locally and submitting them to BioImage can be streamlined significantly, since BioImage can read the image header files, extract the relevant metadata, and use these to populate the submission forms, easing the task of manual submission.
The ultimate extension of this rationale will be the automated uploading of the entire metadata content of studies recorded in a local image asset management database using open source software provided by the Open Microscopy Environment (www.openmicroscopy. org; Swedlow et al., 2003), together with any analytical results associated with such studies. To achieve this, we are working with the developers of the Open Microscopy Environment in two ways. First, BioImage will directly import and export image files and associated metadata recorded in OME-XML, a format that has been adopted as a common image exchange format by the European Light Microscopy Initiative and a number of leading microscope and software manufacturers. Second, we plan to develop a cross-mapping ontology and a BioImage plug-in for the OME system that will allow the automated uploading of selected OME studies from a researcher's local OME database direct to BioImage using Web services protocols, permitting OME users to publish the best of their images and associated analytical results to the BioImage Database without hassle, with the submitters being required to add manually only a minimum amount of additional information for each study.
It is important to note that while most original highresolution multidimensional images will be directly available from the BioImage Database server, this does not have to be the case. Provided that URLs for these original high-resolution multidimensional images are provided and that these images themselves are made permanently available on a stable server elsewhere, they need not reside on the BioImage Database server. However, medium-resolution "Web quality" 2D representative versions of the original images, of at least 512 by 512 pixels, must be submitted to the BioImage Database in PNG, TIFF, or JPEG format at the same time as the metadata relating to them. This permits authors to maintain copyright control over their high-resolution images if so desired (see Section VI). However, the BioImage staff will need initial access to any multidimensional high-resolution images that they will not be hosting directly in order both to check image quality and to extract metadata from the image header files.
IV. HOW TO FIND IMAGES IN THE BIOIMAGE DATABASE
Users can employ several strategies to find images described in the BioImage Database-browsing, searching, or a combination of both.
A. Browsing
After logging on to the BioImage Database, users will immediately be presented with the main browse interface
(Fig. 2). This page will allow users to start their search by selecting an organism type (e.g., plant), a biological process (e.g., cell cycle, reproduction, or motility), a biological specimen (e.g., an organ, tissue, cell type, or organelle), an image type (e.g., electron micrograph), or an image source (e.g., EMBO Journal or University of Oxford). Each main section has several subheadings, and under each subheading the most commonly requested categories in the database are listed. Selecting ">other..." will list all the categories under that subheading. Selecting the "'Homo sapiens-human" category, for example, will immediately list for the user all BioImage studies that contain images of humans, of human tissues, of human cells, and of organelles or macromolecules of human origin.
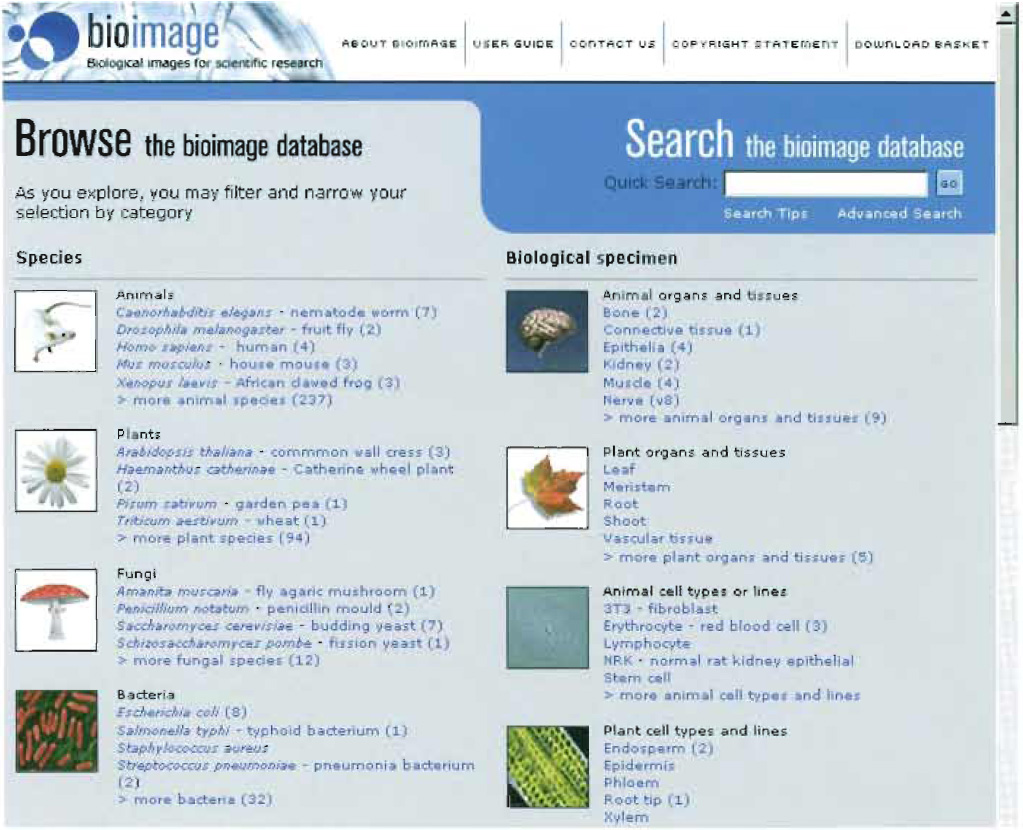 |
| FIGURE 2 Design for the BioImage Database home page and browse interface. |
The results set can be refined at any stage using the grey "Refine Results" panel to the left of the screen-so that, for example, selecting Biological Specimen>Organelle>Golgi apparatus will restrict the results to those that show the human Golgi apparatus.
B. Searching
Browsing and searching within the BioImage Database are complementary and mutually supportive activities, with a search tab always available within the browse window (Fig. 2).
Users can employ two modes of searching:
1. Quick Search Interface, Available from the Browse Window
This permits simple key word or key phrase searching for matching text in all titles, descriptions, categories, and author records.
2. Advanced Search Interface
This window (Fig. 3) appears after clicking the "Advanced search" button beneath the Quick Search box. It permits the use of Boolean operators (and, or, not) between search terms applied to BioImage study titles, descriptions and categories, and enables restriction by author, date, and BioImage identifier. It further permits iterative refinement by reusing previous search results in a manner familiar to users of the bibliographic database software WinSPIRS, as all search results are saved automatically for the duration of a session.
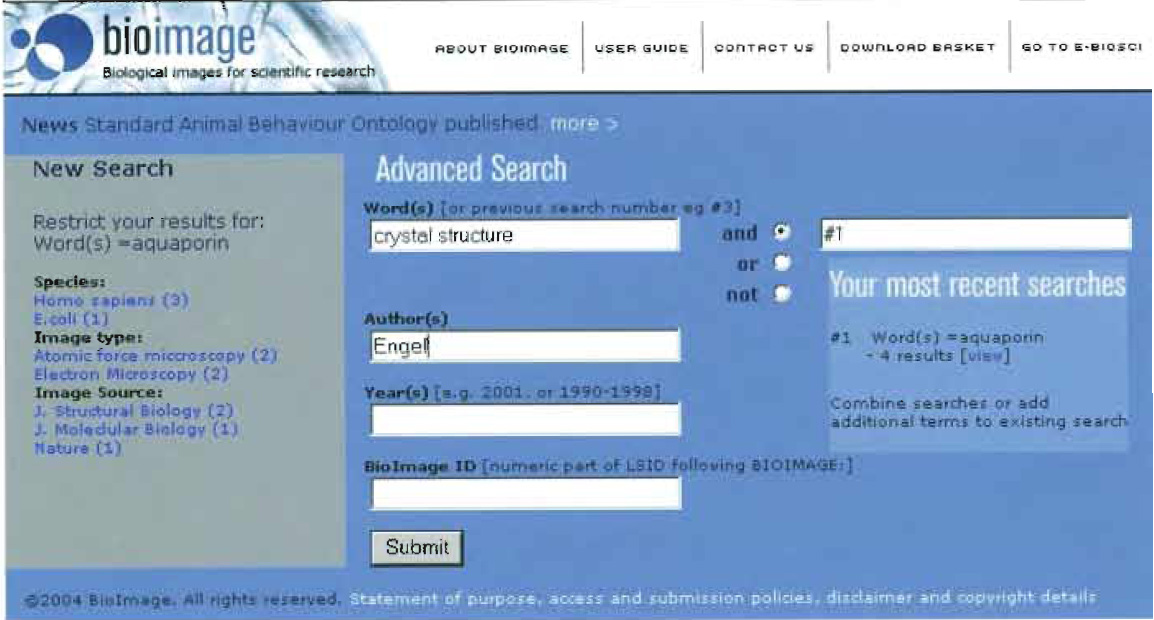 |
| FIGURE 3 The Biolmage Database advanced search interface |
The advanced search interface thus enables users to enter queries of the type: "Retrieve all studies containing images of Drosophila testes showing expression of the gene always early (aly)" by combining the terms "Drosophila testis" and "aly." The user can then link out from the retrieved BioImage studies both to the relevant gene sequences and to literature publications about them.
BioImage text searches should not include "wild cards," as the BioImage text search engine is a reasonably sophisticated tool that looks for matches in word stems and will automatically identify plural forms and other grammatical variants. So, for example, a search for "Kills," "Killing," or "Killed" will all return the study "Killing of mouse L929 fibroblasts by mouse HA-8 cytotoxic lymphocytes (CTL)" but not a study on killifish.
A major goal of the current BioImage Database development is to move away from conventional searching by exact key word matching and instead use ontologies to provide the ability to undertake semantically rich searches that can handle synonyms ("yeast" and "S. cerevisiae"), homonyms ("G protein": does it mean a GTP-binding protein or the coat glycoprotein from Semliki forest virus?), related terms ("cell division" and "mitosis"), and hierarchies ("Mus musculus," "rodent," and "mammal"). A search for "yeast" would thus return studies of S. cerevisiae even if the term "yeast" appears nowhere in the study metadata. The improved accuracy of search and browse results will become increasingly apparent to users of the BioImage Database as these improvements are introduced. Users should check the online "Development status" page for the current status of this work.
C. Viewing Browse and Search Results
Results can be displayed in one of three ways by using the tabs shown at the top of the results page.
1. As a List of Studies
For each study retrieved, the user is shown a representative thumbnail image, the study title, and its brief textual description, the study ID [in the form of a Life Science Identifier (LSID; http://www.i3c.org)], the authors' names, the categories into which the study falls, and the number of image sets and images within the study, as shown in
Fig. 4.
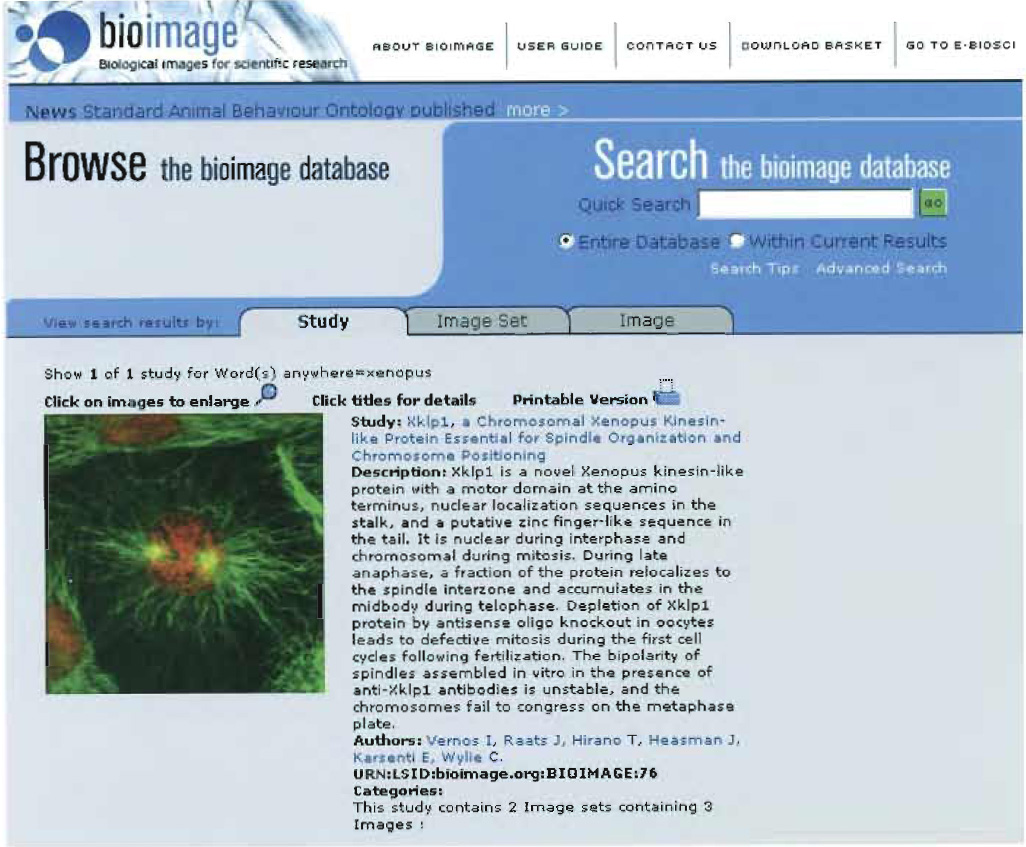 |
| FIGURE 4 The Biolmage Database results interface, showing study results. |
2. As a List of Image Sets
For each image set, the user is similarly shown a representative thumbnail image, the image set title, and its brief textual description, the image set ID, the authors' names, the categories into which the image set falls, the ID and title of the study to which the image set belongs, and the number of images contained within the image set.
3. As an Array of Images
For each image, the user is simply shown a thumbnail image, with the image title and ID, and a list of the versions of that image that are available for download (e.g., for a 3D confocal data set: there may be a Web resolution 2D representative image, a highresolution 2D representative image, a Web resolution 3D image stack, or the original high-resolution 3D image dataset), with check boxes against each option that allows the user to select one or more for downloading, in one or more formats. Mousing over each option will open a transient display giving details of the formats, file sizes, and so on available for each version of the image. For each type of display, clicking on a thumbnail image opens a larger version of the image, whereas clicking on a title will take the user to another page showing more complete metadata relating to the study, the image set, or the image, as appropriate.
The best way of viewing results depends to some extent on the purpose of the search. Users looking for a striking image to illustrate a particular biological topic will probably want to scan the array of images visually, matching their search criteria displayed by using the "Image" tab, whereas users more interested in the significance of the images may prefer the study or image set displays, with their richer metadata descriptors.
Users can move between these alternative display modes by clicking on the relevant tabs (Fig. 4), and the range of results displayed may be progressively refined using the "Refine Results" panel. For example, after an initial selection for all studies relevant to the "Homo sapiens-human" category, it may be that not all the image sets in a particular returned study involved human material. If the study involved a comparison between cellular structures in human and mouse brain, it would be quite likely to contain separate image sets for each. If mouse data were irrelevant to the user's requirements, they could be removed from the image set or image result displays by restricting the display, using the Refine Results panel, to show only "'Homo sapiens-human" results. This area of the database functionality is currently under development, but the ultimate aim is to allow users to navigate hierarchically through each set of categories using taxonomies and ontologies provided by third parties, permitting both restriction and expansion of the scope of displayed results. Again, users should refer to the BioImage online "Development status" page for the current status of this facility.
V. DOWNLOADING IMAGES AND VIDEOS
A. Downloading Images
When viewing image search/browse results, users may mark individual images to be added to their download basket. To review the selected images and to initiate the download, users must select "Download Basket" from the main menu at the top of the browser window. Users will then be asked to confirm their agreement to the BioImage Database conditions of use before beginning the download process. Currently the download process begins immediately once these options have been specified and the download button is clicked, although it may be necessary in the future to schedule downloads to later times if current traffic is high and the requested files are large. Users may wish to check the online "System status" page to determine the current workload on the system.
Together with the downloaded images, users will be sent XML documents containing core metadata relating to the selected images, and to the image sets and studies of which they are a part, unless these are already bundled with the image as an OME-XML file.
B. Customizing Videos
For videos stored within the BioImage Database, we hope shortly to provide two possibilities for customising selected videos before downloading them, both of which depend upon a separate software service entitled VIDOS (Boudier and Shotton, 2000), which is part of a suite of on-line video services that we are developing under the umbrella title of VideoWorks (www.videoworks.ac.uk).
In interactive mode, a BioImage user, having selected a video, can choose the "Customize the video using VIDOS" button. In this case, the video will automatically be made available to the VIDOS server, which will cause a VIDOS customization applet to open in a new browser window on the user's machine. The user can then interactively select the desired spatial and temporal editing parameters for the video and choose the required download format, codec, and compression quality. The VIDOS server then commissions a conversion job that runs on a VIDOS slave processor and finally delivers the customised video file to the user.
The alternative method of using VIDOS is more sophisticated, although less flexible, and depends upon the presence of prerecorded semantic content metadata for the video within the BioImage Database (Shotton et al., 2000; Machtynger and Shotton, 2002; Rodriguez et al., 2004). This permits users to search not just for entire videos, but also for clips from videos containing particular scenes, events, objects, or actors specified in the search. For example, a search might be for any clip showing apoptotic death of a fibroblast induced by a cytotoxic T lymphocyte. The images within any BioImage study returned by this search would include not only the entire video(s) containing such events, which could be downloaded directly or customised interactively as described earlier, but also those named video clips within the complete video(s) containing the specified events. Streaming previews of each such video or video clip could be viewed by clicking on the appropriate thumbnail keyframe image, while selection of a particular clip for downloading in a selected format would trigger a sequence of automated interactions between the BioImage server and the VIDOS sever using Web services protocols that would pass predetermined spatiotemporal editing and format customization parameters to the VIDOS server, commissioning an appropriate VIDOS customization job, and finally returning the requested clip to the user. For efficiency, such clips, once created, would be cached so that they would be available immediately for downloading upon a second request by a different user. While this Web services version of VIDOS has been tested and shown to work in prototype, it has yet to be fully implemented within the BioImage system, and potential users should consult the BioImage online "Development status" page for further information.
VI. COPYRIGHT ISSUES AND LICENSING AGREEMENTS
BioImage encourages users to submit their images under the Creative Commons Public Licence (http://creativecommons.org) that is also used by the Public Library of Science (www.plos.org). This licence, the terms of which are viewable at http://creativecommons.org/licenses/by/1.0/legalcode, grants to the BioImage Database and its end users "a worldwide, royalty-free, nonexclusive, perpetual (for the duration of the applicable copyright) license to exercise the rights in the Work." This effectively provides open access for BioImage Database users to view, download, and use the images, provided that copyright is acknowledged by including the name of the author and the original title of the image in any reproduction or derivative work and by insisting that any subsequent distribution of the image or derivative work is made under the same Creative Commons Public Licence. We believe this approach to be the most appropriate for images created as part of research projects undertaken using public funds and will maximise the potential usefulness of the images.
However, because some people may wish to submit images to the database that may have been created primarily for commercial purposes or may have significant commercial value that the copyright holders wish to retain, the Creative Commons Public Licence is not always appropriate. We therefore alternatively allow images to be submitted and licensed to the BioImage Database for noncommercial use only. Under this agreement, contributing authors retain full copyright to their material. However, they licence to the BioImage Database the right to make the image available to BioImage users, but only for noncommercial purposes and not for financial gain. End users must acknowledge the name of the original author and the source of the images as being the BioImage Database Web site and are legally obliged to contact the copyright holders for permission to reproduce the image outside the terms of this license.
As a further safeguard, authors may submit to the BioImage Database only thumbnail and Web resolution images, as defined earlier, while retaining the original high-resolution image files on their own Web sites, to which potential users must go for access to them, with whatever access and payment regulations that the user requires. The BioImage Database itself will take no part in such commercial transactions.
An alternative safeguard for those submitting images to the BioImage Database under either of the aforementioned licences is the ability to embargo publication of the images until some future date, e.g., until after the publication of that important Nature paper that is dependent upon the information contained within the images. For full details of these licenses and how they are applied, please see the BioImage Web site.
VII. VALUE AND FUTURE POTENTIAL OF THE BIOIMAGE DATABASE
The biological community is currently suffering form a surfeit of information in digital form, including journal publications, sequences and sequence-related information, three-dimensional structures, and digital image data. In 1999, an advisory committee to the U.S. National Institutes of Health estimated that some biomedical laboratories were already producing 100 terabytes of information a year. In the same year, the NCBI reported that 600,000 searches a day were being carried out on its collection of databases (Botstein and Smarr, 1999). In the time since that report, the volume of sequence data to be searched has increased by almost an order of magnitude and the volume of requests has approximately doubled every year. The EMBO DNA sequence database run by the EBI now receives over a million queries a day and is updated once a second (G. Cameron, personal communication, 2003). As David Roos (2001) has said: "We are swimming in a rapidly rising sea of data . . , how do we keep from drowning?"
With the advent of high-throughput cellular screening systems capable of generating 40,000 images a day and of functional MRI scans generating 100Gb of data with each experiment, images are adding significantly to the scale of this data deluge. The integration of such multidimensional image data with the scientific literature and with a rapidly growing set of disparate bioinformatics resources, it is rapidly becoming one of the most demanding challenges for information science. There is an urgent need to better exploit the potential of the Internet and other communication networks to help researchers navigate through what is becoming an intricate and confusing information landscape. This need can be met in part by providing research communities with sophisticated tools to manage large complex multimedia datasets. The BioImage Database is one such tool.
We therefore invite you to use and to tell your colleagues about the BioImage Database and to submit your best images for publication within it, thereby not only maximizing exposure of your research achievements, but also ensuring that in 10 year's time you will know where to find your images in a format in which they can still be viewed!
References
Botstein, D., and Smarr, L. (co-chairs) (1999). Report of the Advisory Committee to the Director, NIH Working Group on Biomedical Computing. Available online at http://www.nih.gov/about/ director/060399.htm.
Boudier, T., and Shotton, D. M. (2000). VIDOS, a system for video editing and format conversion over the Internet. Comput. Networks 34, 931-944.
Carazo, J. M., and Stelzer, E. H. K. (1999). The BioImage Database Project: Organizing multidimensional biological images in an object-relational database. J. Struct. Bio. 125, 97-102.
Carazo, J. M., Stelzer, E., Fita, I., Henn, C., Machtynger, J., McNeil, P., Shotton, D. M., Chagoyen, M., Alarcon, P. A., Lindek, S., Fritsch, R., Heymann, B., Kalko, S., Pittet, J.-J., Rodriguez-Tome, P., and Boudier, T. (1999). Organizing multidimensional biological microscopic image information: The BioImage database. Nucleic Acid Res. 27, 280-283.
Catton, C., and Shotton, D. M. (2002). Making sense of images: Ontologies and the BioImage database. Proc. Standards and Ontologies for Functional Genomics, Hinxton, November, 2002. Available at http://www.bioimage.org/publications.do.
Catton, C., and Shotton, D. M. (2003). "What is that crow thinking?" Separating fact and hypothesis in the BioImage Database. Proc. 2nd e-BioSci/ORIEL Summer Conference Beating the Data Deluge, Varenna, Italy, Sept 2-5, 2003. Available online at http://www.bioimage.org/publications.do.
Lindek, S., Fritsch, R., Machtynger, J., de Alarcon, P. A., and Chagoyen, M. (1999). Design and realization of an on-line database for multidimensional microscopic images of biological specimens. J. Struct. Bio. 125, 103-111.
Machtynger, J., and Shotton, D. M. (2002). VANQUIS, a system for the interactive semantic content analysis and spatiotemporal query by content of videos. J. Microsc. 205, 43-52.
Rodriguez, A., Guil, N., Shotton, D. M., and Trelles, O. (2004). Automatic analysis of the content of cell biological videos, and database organization of their metadata descriptors. IEEE Transact. Multimedia 6, 119-128.
Roos, D. S. (2001). Computational biology: Bioinformaticsmtrying to swim in a sea of data. Science 291, 1260-1261.
Shotton, D. M. (2003). The BioImage Database: Multidimensional research images and their relationship to the wider online research information environment for the life sciences. Proc. E-BioSci Mtg. Biological Information Management: Challenges and Choices. NeSC, Edinburgh, 28/4/03. Online at http://www.bioimage.org/publications.do.
Shotton, D. M., Catton, C., and Sparks, S. (2003). BioImage: From image database to Grid service. Proc. 2nd e-BioSci/ ORIEL Summer Conference Beating the Data Deluge, Varenna, Italy. Available online at http://www.bioimage.org/ publications.do.
Shotton, D. M., Rodriguez, A., Guil, N., and Trelles, O. (2000). Object tracking and event recognition in biological microscopy videos. In "Proc. 15th International Conference on Pattern Recognition: ICPR 2000," Barcelona, Spain (3-8 September 2000) 4, 226-229.
Shotton, D. M., Rodriguez, A., Guil, N., and Trelles, O. (2002). A metadata classification schema for semantic content analysis of videos. J. Microsc. 205, 33-42.
Sparks, S., and Shotton, D. M. (2003). The application of ontologies to the BioImage database. Proc. 2nd e-BioSci/ORIEL Summer Conference Beating the Data Deluge, Varenna, Italy. Available online at http://www.bioimage.org/publications.do.
Swedlow, J. R., Goldberg, I., Brauner, E., and Sorger, P. K. (2003). Informatics and quantitative analysis in biological imaging. Science 300, 100-102.
Support our developers




