As earlier discussed, a mutation will involve a change in the sequence of nucleotides in a nucleic acid molecule. This change will express itself in the from of a change in the sequence of amino acids in the protein molecule synthesized through the information encoded in nucleic acid segment. Therefore, mutations at the molecular level can be studied both by the study of the sequence of amino acids in a protein and also by the study of sequence of nucleotides in a segment of nucleic acid. Studies have been conducted during the last 30 years, where amino acid sequences in proteins and nucleotide sequences in nucleic acid segments could be determined by the development of newer techniques.
The most notable in this connection is the work done by
Frederick Sanger who worked at the Laboratory of Molecular Biology at Cambridge and was awarded Nobel Prize twice,
first in chemistry for his work on amino acid sequence of
insulin molecule and
second in medicine for his work on complete nucleotide sequence in a bacteriophage Φ X 174. While the technique of amino acid sequence determination was first developed by Sanger, the technique for determination of nucleotide sequence in nucleic acid was developed initially by
Robert W. Holley, another Nobel Laureate, and later by Maxam and Gilbert (degradation method), and Frederick Sanger (dideoxynucleotide synthetic method) (see
Genetic Engineering and Biotechnology 3. Isolation, Sequencing and Synthesis of Genes). These techniques were subsequently modified by several workers to bring about automation in sequencing techniques.
Sanger's technique for amino acid sequence determination
Sanger's technique enabled identification of terminal amino acids, at both ends i.e. N-terminal end as well as C-terminal end. For this purpose specific dyes were used which will react specifically with N- and C-terminal amino acids giving differently coloured compounds. The N- and C-terminal amino acids could be separated after hydrolysis of protein followed by chromatography and could then be identified. If peptide chains are broken into smaller segments, N and C terminal amino acids of these segments could also be identified. Thus a number of interior amino acids could also be identified. Like a puzzle, using short sequences, complete sequence could be determined in a manner so that the complete sequence should easily explain smaller sequences. Almost similar technique was used by Robert Holley for determining the sequence of yeast alanine
transfer RNA molecule.
Altered amino acid sequences in mutants
Alterations in amino acid sequences due to mutations can be explained with the help of a few examples of proteins, where amino acid sequences have been worked out both in the normal as well as mutant individuals. The details of mechanisms involved in several of these cases
(silent, neutral, missence and
nonsense mutations) are explained with the help of the Genetic Code and are therefore discussed in
The Genetic Code.
Sickle cell anemia and sickle cell trait. The human blood disease sickle cell anaemia is due to abnormal hemoglobin S and homozygous genotype
HbS HfS. Sickle cell trait, on the other hand, is due to heterozygous genotype
HbS HBA, the normal individuals being
HbA HbA and having hemoglobin A. A third abnormal hemoglobin C due to gene
Hbc has also been identified. A complete hemoglobin molecule consists of four polypeptide chains having two identical α (alpha) chains and two identical β (beta) chains, αand β chains being different but each having about 140 amino acids. Therefore, for complete structure a sequence of 280 amino acids was to be worked out both in normal and sick human beings.
V.M. Ingram modified
Sanger's original method for the study of amino acid sequence and used his
fingerprinting technique, in which hemoglobin after trypsin digestion was resolved into 30 spots with the help of a technique using electrophoresis and chromatography. W.hen these spots were compared in hemoglobins A, S and C, a single spot (spot 4) was found to have different positions in three hemoglobins and therefore, only this peptide segment (which had about 8 amino acids) was considered to be modified and its amino acid sequence was determined, showing a change at only 6th position as shown below; this is described as a
missense mutation,

Subsequently, the complete amino acid sequence of αchain and β chain were determined and variations in sequences were reported. It was also shown that separate genes are responsible for the synthesis of α and β chains. Since no variations in amino acid sequences were found in normal hemoglobin, this example shows drastic influence of a change in single amino aicd in a protein having 560 amino acids (2 chains of α and 2 chains of β, each 140 amino acids). There may, however, be other cases where changes in one or two amino acids do not affect the phenotype as in insulin.
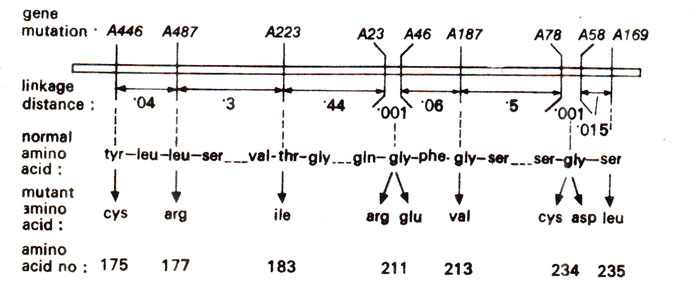
Fig. 23.39. Colinearity between gene mutations on linkage map and amino acid replacements in protein as studied by Yanofsky and his coworkers in tryptophan synthetase enzyme in E. coli.
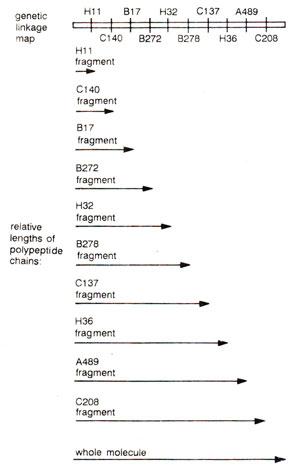
Fig. 23.40. Colinearity between a number of amber mutations on the linkage map and the size of polypeptide chain as studied by Sarabhai and co-workers for head protein of T4 phage.
Tryptophan synthetase and colinearity hypothesis. A study of amino acid sequence in different mutants of tryptophan synthetase and the mapping of these mutants on a genetic linkage map revealed a very interesting correlation. In 1964,
C. Yanofsky and his co-workers observed that different mutations on the genetic map were present in the same order as is observed in the alterations noticed in corresponding amino acid sequence in polypeptide chain A of the enzyme in
E. coli. This colinear relationship is shown in detail in Figure 23.39 and was put forward as
colinearity hypothesis.
Fig. 23.39. Colinearity between gene mutations on linkage map and amino acid replacements in protein as studied by Yanofsky and his coworkers in tryptophan synthetase enzyme in E. coli.
Amber (nonsense) mutations and colinearity in head protein of T4 phage. Colinearity between nucleotide sequence in nucleic acid and amino acid sequence in protein was also demonstrated in another popular example, where amber mutants in head protein of bacteriophage T4 were studied. Amber mutants (see
The Genetic Code) lead to premature termination of the synthesis of a polypeptide chain so that the polypeptide obtained will be relatively smaller in size. These mutants are unable to grow on
E. coli strains not having suppressor for these mutations.
A. Sarabhai and co-workers demonstrated that different amber mutants produced polypeptides of different lengths for head protein in bacteriophage T
4. These mutants were arranged in increasing order of length, e.g. A<B<C<D<E, etc., so that A has smallest polypeptide chain and the normal T
4 head protein has longest polypeptide. When the mutants were mapped on chromosome, they had a linear order which corresponded with the increasing order of the lengths of polypeptides produced by them, thus establishing a colinearity between the order of nucleotides on chromosome and amino acid sequence in the protein (Fig. 23.40). This example is another evidence supporting
colinearity hypothesis discussed above.
Fig. 23.40. Colinearity between a number of amber mutations on the linkage map and the size of polypeptide chain as studied by Sarabhai and co-workers for head protein of T4 phage.




