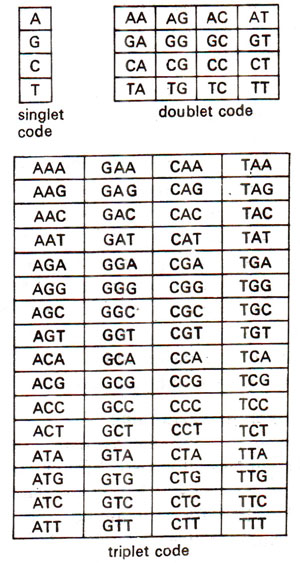
Fig. 30.1. A singlet code, a doublet code and a triplet code.
In
Chemistry of the Gene 1. Nucleic Acids and Their Structure, it has been shown that all genetic information is stored in the nucleic acids (DNA or RNA). As will be shown later in
Expression of Gene : Protein Synthesis 2. Transcription in Prokaryotes and Eukaryotes, it is also known that the genetic information in the nucleic acids is expressed through synthesis of proteins. As we know, while proteins have 20 different kinds of essential amino acids, nucleic acid (particularly in living cells) has only four different kinds of bases. (Recently, it has been shown that in artificially synthesized DNA segments, the number of bases can extend to more than four i.e. 6 or 8). It may therefore, be realized that while 20 amino acids are the alphabets of the language of proteins, four bases are the alphabets of the language of nucleic acids. Since it is through mRNA (messenger RNA, see
Expression of Gene : Protein Synthesis 2. Transcription in Prokaryotes and Eukaryotes) that the genetic information is passed on to proteins, the problem of genetic code was to prepare a dictionary for translating the language of RNA into the language of proteins. Since one is four alphabet language and the other has 20 alphabets, as shown in Figure 30.1, a singlet code would give only four codons, a doublet code would have 16 codons and triplet code would give us 64 (4 x 4 x 4) triplets. The 64 triplets would be enough to code for 20 amino acids.
In a 64-codons dictionary, either there should be more than one triplets coding for the same amino acid or else, of the 64 triplets, 44 triplets should mean nothing (nonsense). It has now been proved by experimental evidence that the code is triplet and that all 64 codons carry some meaning, although three of these 64 triplets cannot be translated in terms of amino acids, since they mean stop signals. Whenever any one of these three triplets is encountered on mRNA, it orders that the end of the polypeptide chain has reached and that the chain should now be released, before further synthesis may take place.
Fig. 30.1. A singlet code, a doublet code and a triplet code.




